
跟着年夜模子在长文本处置义务中的利用日益普遍,怎样客不雅且精准地评价其长文天性力已成为一个亟待处理的成绩。传统上,迷惑度(Perplexity, PPL)被视为权衡模子言语懂得与天生品质的尺度指标——迷惑度越低,平日象征着模子对下一个词的猜测才能越强。因为长文本可被视为个别文本的扩大,很多研讨天然地经由过程展现模子在长文本上的低迷惑度来证实其长文本泛化才能的无效性。但你晓得,这个评价方法可能完整错了吗?近期研讨发明,迷惑度在长文本义务中的实用性存在明显范围性:某些在迷惑度指标上表示优良的模子,在现实长文本利用中却未能到达预期后果。如图 1(上)所示,在 9 种主流长文本年夜模子上,迷惑度(y 轴)与模子在长文本义务中的实在表示(x 轴)之间的相干性极低。这一变态景象引出了一个要害成绩:为何迷惑度(PPL)在长文本场景下生效?
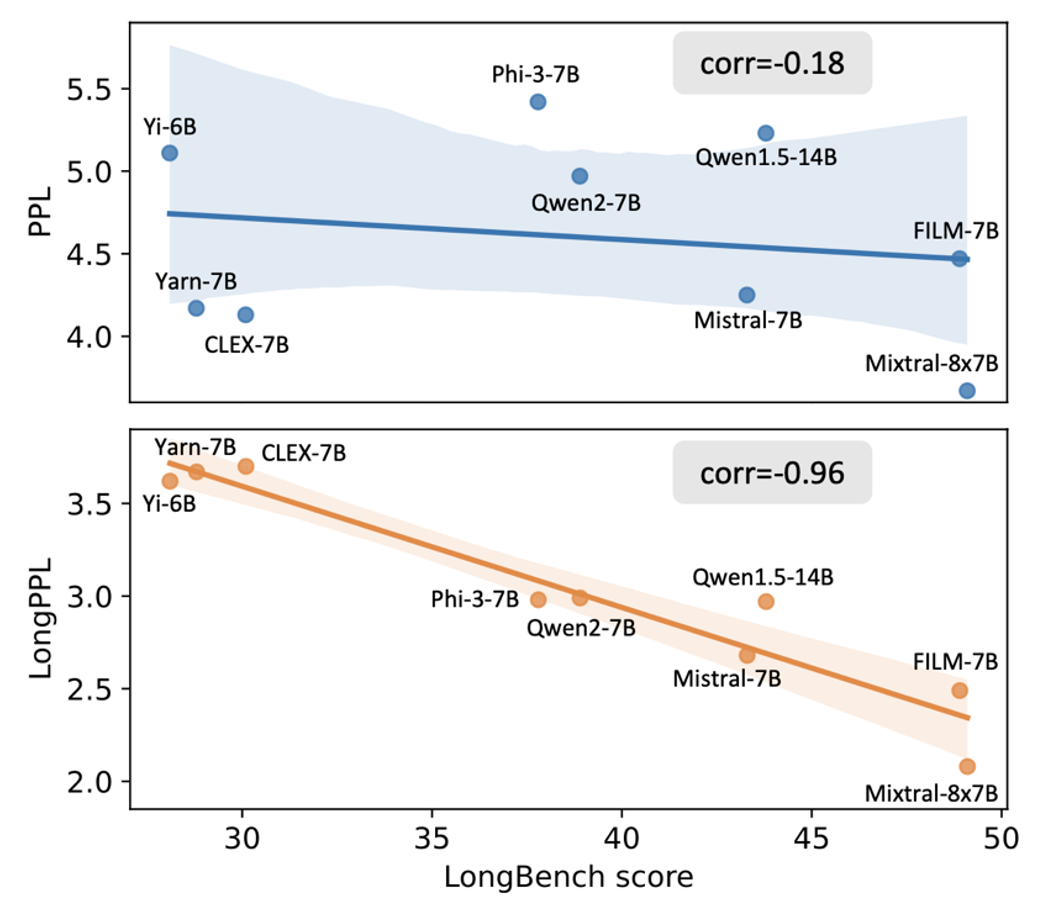
图 1 年夜模子的迷惑度 (PPL) 跟长文本迷惑度 (LongPPL) 与长文本义务集 LongBench 分数的相干性。针对这一成绩,北京年夜学王奕森团队与 MIT、阿里一道发展了深刻研讨,探究迷惑度在长文本义务中生效的起因,并提出全新指标 LongPPL,更精准反应长文天性力。经由过程试验,他们发明长文本中差别 token 对长间隔高低文信息的依附水平存在明显差别。此中,对长高低文信息依附较强的 token 在评价模子的长文本处置机能时起到要害感化,但这类 token 在天然文本中只占多数。这标明,迷惑度生效的起因在于其对全部 token 停止均匀盘算,无奈充足存眷这些与长文天性力关联亲密的要害 token。为此,他们将迷惑度的盘算限度在长文本的要害 token 上,从而界说出可能反应模子长文本处置才能的长文本迷惑度(LongPPL),该指标表示出与长文本义务机能极高的相干性 (如图 1(下))。别的,他们还基于这一计划思维提出长文本穿插熵丧失(LongCE),明显晋升了模子经由过程微调加强长文本处置才能的后果。

论文标题: What is Wrong with Perplexity for Long-context Language Modeling?论文地点: https://arxiv.org/abs/2410.23771代码地点: https://github.com/PKU-ML/LongPPL并非全部 token 都反应模子长文天性力为探究迷惑度在长文本义务中生效的起因,作者起首剖析了长文本与漫笔本在实质上的差别。直不雅来看,一段文本中差别词语对长间隔高低文的依附水平存在明显差别。比方,在小说中,某个情节的开展可能须要与数章之前埋下的伏笔相响应,而某些语法上的牢固搭配则平日无需依附较远的高低文。在长文本场景下,这种依附水平的差别较漫笔本更为明显。为了量化并验证这始终不雅意识,本文起首斟酌了一个简略的义务场景——LongEval 长文本键值对检索义务(图 2(a))。在此义务中,模子依据成绩在长高低文中检索出与给定键相婚配的值。本文将成绩的尺度答复分别为非谜底局部(蓝色)跟谜底局部(橙色)。显然,非谜底局部的天生仅依附短高低文,即最后的问句内容;而谜底局部则须要模子聚焦于完全的长高低文信息。图 2 (b)(c) 标明,谜底局部的迷惑度与模子在此义务中的现实表示高度相干,而非谜底局部的迷惑度多少乎与义务表示有关。由此可见,依附长高低文信息的要害 token 在评价模子的长文天性力时愈加主要。